
Lieferscheine, CMR, Rechnungen: Wo KI Logistik-Dokumente wirklich entlastet
Welche Dokumente sich als KI-Startfall eignen, was automatisiert werden darf und warum Prüfung, Pflichtfelder und Übergabe von Anfang an sauber sein müssen.

Lieferscheine. CMR. Packlisten. Rechnungen. Abliefernachweise. In vielen Logistikteams sind Dokumente der Ort, an dem digitale Prozesse plötzlich wieder manuell werden.
Die Ware bewegt sich längst durch Systeme. Aber der Nachweis hängt als Scan in einer E-Mail. Eine Referenznummer steht anders als im ERP. Eine Menge weicht ab. Ein PDF muss einem Vorgang zugeordnet werden. Eine Rechnung wartet, weil ein Feld fehlt.
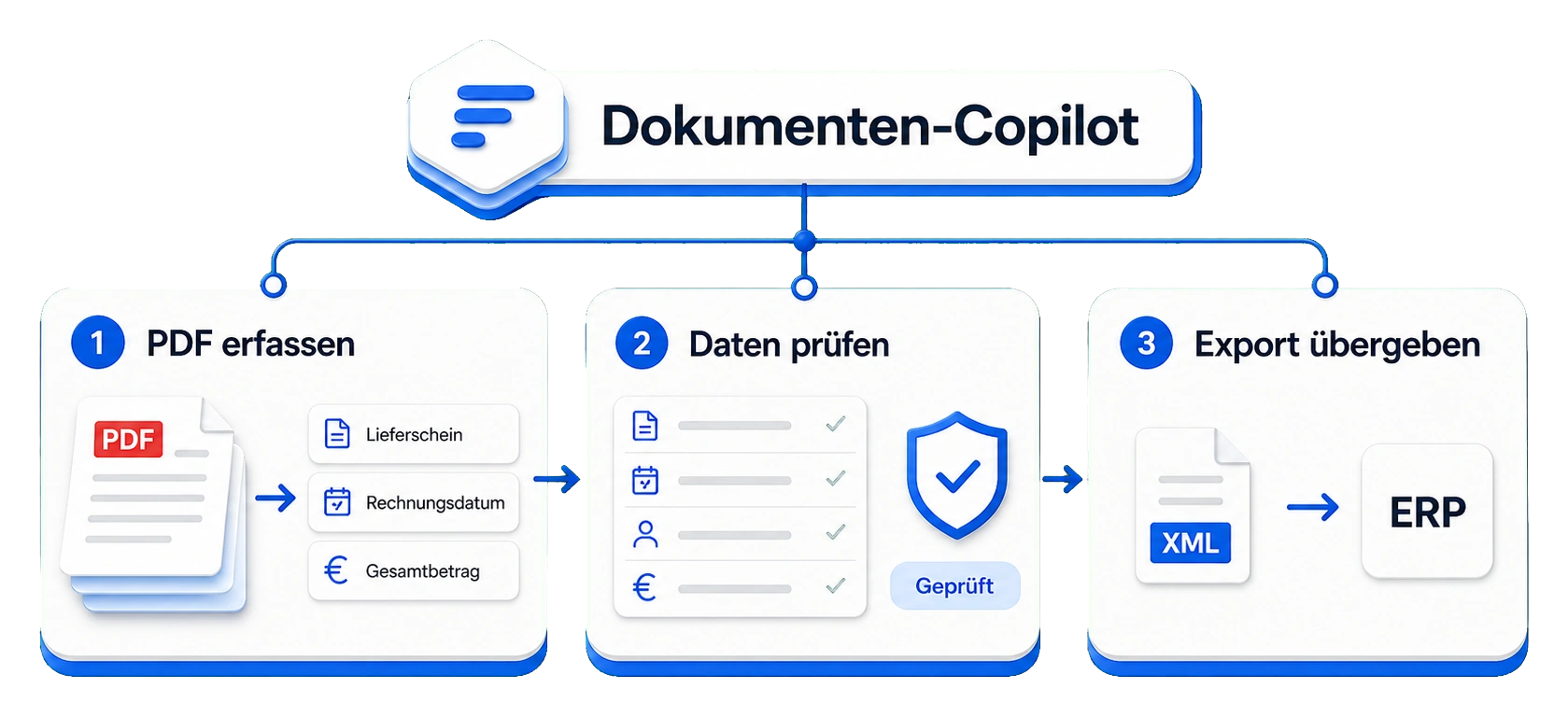
Genau hier kann KI helfen - nicht als Zauberschicht, sondern als Dokumenten-Copilot im Arbeitsfluss. Der Copilot erkennt Dokumenttypen, liest relevante Felder aus, markiert Unsicherheiten und bereitet die Übergabe vor. Das Team prüft, entscheidet und gibt frei.
Warum Dokumentenarbeit in der Logistik so viel Reibung erzeugt
Logistikdokumente sind selten einheitlich. Selbst wenn sie fachlich dieselbe Funktion haben, sehen sie unterschiedlich aus:
- Kundenvorgaben
- Carrier-Layouts
- Scans und Fotos
- internationale Begriffe
- handschriftliche Ergänzungen
- fehlende Seiten
- schlechte Bildqualität
- unterschiedliche Nummernlogiken
Diese Vielfalt trifft auf Prozesse, die eigentlich Präzision brauchen. Ein falsches Datum, eine fehlende Referenz oder eine nicht erkannte Mengenabweichung kann Abrechnung, Kundenkommunikation oder Reklamationsbearbeitung verzögern.
Der eigentliche Engpass ist dabei oft nicht das Lesen eines einzelnen Dokuments. Der Engpass ist die Kette:
- Dokument empfangen
- Dokumenttyp erkennen
- Vorgang finden
- Pflichtfelder auslesen
- Abweichungen prüfen
- Freigabe oder Rückfrage auslösen
- Daten ins Zielsystem übertragen
- Nachvollziehbarkeit sichern
Wenn diese Kette täglich hunderte Male läuft, wird sie teuer.
Welche Dokumenttypen sich besonders eignen
Für einen ersten KI-Ablauf sollten die Dokumenttypen häufig, ähnlich und geschäftlich relevant sein.
Lieferscheine
Gute Startfälle, weil sie meist wiederkehrende Pflichtfelder enthalten:
- Lieferant
- Empfänger
- Datum
- Artikel- oder Positionsdaten
- Mengen
- Referenznummer
- Unterschrift oder Empfangsvermerk
KI kann hier auslesen, zuordnen und Abweichungen vorbereiten. Entscheidend ist, dass Mengen- und Referenzlogik sauber definiert sind.
CMR-Frachtbriefe
CMR-Dokumente sind fachlich stark relevant, aber formell nicht immer sauber ausgefüllt. Ein Ablauf sollte deshalb nicht nur Werte extrahieren, sondern fehlende oder unsichere Felder markieren.
Typische Prüfpunkte:
- Absender
- Empfänger
- Frachtführer
- Warenbeschreibung
- Anzahl Packstücke
- Gewicht
- Übernahme- und Ablieferdatum
- Unterschriften
- Vorbehalte
Packlisten
Packlisten helfen bei Zuordnung und Plausibilität. Sie werden besonders wertvoll, wenn sie mit Bestellung, Lieferung oder Wareneingang abgeglichen werden.
KI kann hier Tabellenstrukturen erkennen, Positionen normalisieren und auffällige Unterschiede markieren. Der Mensch entscheidet, ob die Abweichung fachlich relevant ist.
Rechnungen und Gutschriften
Rechnungen haben hohen wirtschaftlichen Hebel, aber auch höhere Kontrollanforderungen. Hier braucht es klare Freigabe, Rollen und Prüfung-Spur.
Für den Start eignet sich oft nicht die komplette Rechnungsfreigabe, sondern ein vorgelagerter Schritt:
- Dokument erkennen
- Pflichtfelder auslesen
- Vorgang oder Bestellung vorschlagen
- offensichtliche Abweichungen markieren
- an die verantwortliche Person routen
Abliefernachweise
Proof of Delivery ist häufig ein starker Fall, weil die Information später für Kundenservice, Abrechnung und Reklamationen benötigt wird. Der Ablauf muss aber besonders sauber mit Bildqualität und Unterschriften umgehen.
Was KI gut kann - und was nicht
KI ist stark bei Mustern, Varianten und Sprache. Sie kann Dokumente verstehen, auch wenn Layouts wechseln. Sie kann relevante Informationen aus Fließtext, Tabellen und Scans zusammenführen. Sie kann unsichere Felder kennzeichnen.
Aber KI sollte nicht so eingesetzt werden, als wäre jeder extrahierte Wert automatisch wahr.
Realistische Stärken:
- Dokumenttyp erkennen
- Felder extrahieren
- Begriffe normalisieren
- Tabellen grob strukturieren
- Vorgangszuordnung vorschlagen
- Dubletten und fehlende Angaben markieren
- Prüfnotizen erzeugen
Grenzen:
- schlechte Scans bleiben schlechte Scans
- unlesbare Handschrift bleibt unsicher
- fachliche Ausnahmen brauchen menschliche Entscheidung
- rechtliche Freigaben gehören nicht in eine Blackbox
- fehlende Systemdaten können nicht herbeigedacht werden
Ein guter Ablauf zeigt deshalb Unsicherheit offen an. Das ist kein Qualitätsmangel, sondern Teil der Betriebssicherheit.
Der Zielzustand: vorbereiten statt blind verbuchen
Ein belastbarer erster Dokumenten-Ablauf sieht oft so aus:
- Dokument kommt per E-Mail, Upload oder Ordner an.
- System erkennt Dokumenttyp und Sprache.
- Relevante Felder werden ausgelesen.
- Vorgang, Kunde, Bestellung oder Lieferung werden vorgeschlagen.
- Abweichungen und Unsicherheiten werden markiert.
- Mitarbeitende prüfen in einer kompakten Ansicht.
- Nach Freigabe werden Daten übergeben oder eine Aufgabe ausgelöst.
- Entscheidung, Quelle und Korrektur bleiben nachvollziehbar.
Der Nutzen entsteht an mehreren Stellen gleichzeitig: weniger manuelles Tippen, weniger Sucharbeit, schnellere Rückfragen, bessere Übergaben und weniger Fehler, die erst später auffallen.
Datenschutz und Prüfung gehören von Anfang an dazu
Dokumentenautomatisierung ist fast immer ein Datenschutz- und Regeln und Verantwortung-Thema. Dokumente können personenbezogene Daten, Kundendaten, Lieferantendaten oder vertrauliche Geschäftsinformationen enthalten.
Vor dem Pilot sollten deshalb mindestens diese Fragen geklärt sein:
- Welche Datenklassen kommen in den Dokumenten vor?
- Welche Anbieter oder Modelle verarbeiten die Daten?
- Werden Daten gespeichert, trainiert oder nur verarbeitet?
- Wo liegen die Daten geografisch?
- Wer hat Zugriff auf Originaldokumente und Extraktionsergebnisse?
- Welche Lösch- und Aufbewahrungslogik gilt?
- Welche Entscheidung muss dokumentiert werden?
Der Europäische Datenschutzausschuss hat in seiner Stellungnahme zu KI-Modellen betont, dass Fragen zu personenbezogenen Daten, Anonymität und Rechtsgrundlage im Einzelfall geprüft werden müssen. Für Mittelstandsteams heißt das praktisch: Datenschutz nicht am Ende an den Pilot kleben, sondern im Datenpfad mitdenken.
Quelle: EDPB Opinion zu KI-Modellen und DSGVO
Wann Dokumente ein guter erster KI-Fall sind
Der Fall ist stark, wenn:
- jeden Tag viele ähnliche Dokumente ankommen
- Pflichtfelder wiederkehren
- Fehler oder Verzögerungen wirtschaftlich spürbar sind
- Zielsysteme oder Exporte vorhanden sind
- ein Team ohnehin prüft und freigibt
- Dokumenttypen klar begrenzt werden können
Der Fall ist schwächer, wenn:
- Dokumente sehr selten auftreten
- jedes Dokument eine Sonderlogik braucht
- Scans kaum lesbar sind
- Zielsysteme keine Übergabe erlauben
- niemand Verantwortung für Freigabe und Korrektur übernimmt
Wie ein Pilot sinnvoll geschnitten wird
Wir würden nicht mit „alle Dokumente automatisieren“ starten. Das ist zu groß und zu unscharf.
Besser ist eine klare Scheibe:
- ein Eingangskanal
- zwei bis drei Dokumenttypen
- definierte Pflichtfelder
- eine Prüfansicht
- ein Zielsystem oder Übergabeformat
- klare Messung nach einigen Wochen
Beispiel: „Eingehende Lieferscheine und Abliefernachweise aus der Service-Inbox erkennen, Pflichtfelder extrahieren, Lieferung vorschlagen und unsichere Fälle markieren.“
Das ist konkret genug, um entwickelt und gemessen zu werden. Danach kann der Ablauf erweitert werden.
Typische Messpunkte
Ein Dokumentenpilot sollte nicht nur technisch bewertet werden. Die operativen Fragen sind wichtiger.
Sinnvolle Messpunkte:
- Dokumente pro Tag
- Anteil korrekt erkannter Dokumenttypen
- Anteil korrekt extrahierter Pflichtfelder
- durchschnittliche Prüfzeit pro Dokument
- Anzahl manuell korrigierter Felder
- Anzahl früher erkannter Abweichungen
- Zeit bis Übergabe an ERP, TMS oder Abrechnung
- Rückfragen aus nachgelagerten Teams
Gerade die Korrekturen sind wertvoll. Sie zeigen, wo der Ablauf noch lernen, Regeln brauchen oder Dokumentqualität verbessern muss.
Was wir bei Fluxward daraus machen
Für uns ist Dokumentenautomatisierung kein isoliertes Texterkennung-Projekt. Es ist ein operativer Ablauf:
Eingang -> Verstehen -> Zuordnen -> Prüfen -> Freigeben -> Übergabe -> Nachvollziehbarkeit.
Wenn dieser Fluss sauber ist, kann KI sehr viel Arbeit vorbereiten. Wenn er unsauber ist, produziert KI nur schnelleres Durcheinander.
Deshalb klären wir zuerst:
- Welche Dokumente haben echten Hebel?
- Welche Felder entscheiden über Arbeit oder Risiko?
- Wo bleibt der Mensch prüft mit?
- Welche Daten dürfen wohin?
- Wie wird Erfolg gemessen?
- Was passiert mit Ausnahmen?
Wenn Sie das sauber sortieren möchten, ist die KI-Potenzialanalyse oft der beste Einstieg. Wenn der Dokumentenfall schon klar ist, passt die individuelle KI-Implementierung, um aus Dokumentenarbeit einen belastbaren Prüf- und Übergabefluss zu umsetzen.

Co-Founder · Kunden, Rollout, Operations

KI nutzen, ohne Datenchaos zu riskieren: Was in Ihre Richtlinie gehört
Eine gute KI-Richtlinie muss nicht lang sein. Sie klärt erlaubte Tools, Datenklassen, verbotene Fälle, fachliche Prüfung, Verantwortung und Aktualisierung.
Weiterlesen
Führungskräfte sollen KI einordnen? Diese 5 Punkte müssen sitzen
Führung braucht mehr als Toolwissen: Versprechen einordnen, gemeinsame Sprache schaffen, Regeln klären, Hebel priorisieren und Umsetzung als Führungsaufgabe verstehen.
Weiterlesen
KI-Strategie-Workshop ohne Folienfriedhof: So kommen Sie zu Entscheidungen
Ein guter Workshop endet nicht mit Ideensammlung, sondern mit Zielbild, priorisiertem Hebel-Portfolio, Regeln, 30/60/90-Tage-Plan und erstem Pilot.
WeiterlesenNächster sinnvoller Schritt
Lassen Sie uns Ihren konkreten KI-Hebel sauber einordnen.
Wenn Sie sich im Artikel wiedererkennen, sortieren wir in 30 Minuten Engpass, Datenlage und nächsten Schritt, ohne Pitch-Druck und ohne KI-Theater.
- Engpass konkretisieren
- Datenlage prüfen
- Pilotpfad klären